
Typically, fine-tuning a model improves its performance in specific skills, topics, and scenarios. That’s why it came as a surprise when one LLM developer had a model show a nearly 5X increase in a specific error type after ingesting a fine-tuning dataset created by their in-house team.
While such increases in errors, biases, and hallucinations are problematic for general-purpose AI models, they can have especially devastating consequences in regulated industries like healthcare, finance, or insurance.
Imagine deploying an AI application at a hospital, only to find that it occasionally misidentifies a specific type of medication. This use case is niche enough that the errors may have been missed during a general model evaluation guided by industry benchmarks — and the consequences can span from financial and reputational damage to patient harm.
This example highlights a central challenge in AI today: ensure models are accurate, reliable, and compliant enough for deployment — especially in high-stakes environments. Despite the hype, many AI initiatives in regulated sectors remain blocked as AI teams attempt to mitigate risks like hallucinations, bias, and inaccuracies in real-world applications.
There’s no universal regulatory body that defines “good AI.” No external authority exists to legitimize whether a model is compliant or trustworthy. That leaves organizations asking: How do we build reliable AI systems and gain trust—both internally and externally?
The risks of deploying AI in regulated industries
The risks associated with deploying models that may be prone to inaccuracies, errors, and biases unbeknownst to AI developers are many. They include:
Reputational risk: Losing user and customer trust
Errors, hallucinations, or biased outputs can severely damage an organization’s reputation. In industries where trust is paramount, like healthcare and finance, a single AI misstep can lead to public backlash, customer attrition, and long-term brand damage.
Regulatory compliance and auditability
Strict regulations like HIPAA, GDPR, PCI-DSS, and Fair Lending laws require that AI models meet specific compliance standards. Rigorous evaluations ensure that models adhere to these rules and can produce audit-ready documentation, safeguarding organizations against regulatory penalties.
Bias and fairness mitigation
AI systems must operate fairly and transparently, especially in critical areas like lending and medical diagnosis. Unchecked biases can lead to unfair loan denials, misdiagnoses, or discrimination, exposing organizations to lawsuits and sanctions. Evaluations help identify and correct biases before models are deployed.
Reliability and performance assurance
Mission-critical applications need AI that works consistently and accurately. Evaluations assess model performance across dimensions like accuracy, robustness, and consistency, ensuring that models perform well in real-world conditions — not just in training environments.
Risk reduction and security
Faulty predictions in banking (e.g., fraud detection or loan approvals) or healthcare (e.g., diagnostic recommendations) can have severe financial and ethical consequences. Evaluation frameworks help catch and correct issues early, reducing the risk of harm or financial loss.
Trust and transparency
Regulated industries require AI systems to be explainable and interpretable. Evaluations provide insight into why models make specific decisions, enabling organizations to build trust with stakeholders and meet legal transparency requirements.
The benefits of third party model evaluations
Just like financial audits or compliance checks, neutral third-party evaluations offer something internal teams can’t: objective, unbiased assessment. Third-party evaluators are not only more likely to be honest, but also bring deep expertise and structured methodologies to the table. They help organizations:
- Identify blind spots or unconscious bias that internal teams might overlook
- Validate models against external standards and best practices
- Provide credibility with external stakeholders, including regulators and customers
In industries where safety, accuracy, and trust are non-negotiable, independent validation is essential.
Why custom model evaluations are more effective than generic benchmarking
Generic benchmarks that tell you whether a model “works” or “doesn’t work” according to broad and rigid standards are overly simplistic and tend to miss nuances. They can fail to identify performance issues that deeply impact usability in specific scenarios and use cases essential to your application.
Even when these benchmarks do identify a performance issue, they don’t pinpoint exactly what’s wrong, let alone the cause of the error and a clear path to fix it. This is where custom evaluations make a critical difference.
Rather than offering vague performance metrics, custom evaluations help diagnose specific failure modes in your model. They tell you:
- Where and why your model is underperforming, focused on the specific scenarios and use cases important to your needs
- What data or logic is contributing to each error type
- How to build fine tuning datasets to strategically address each error
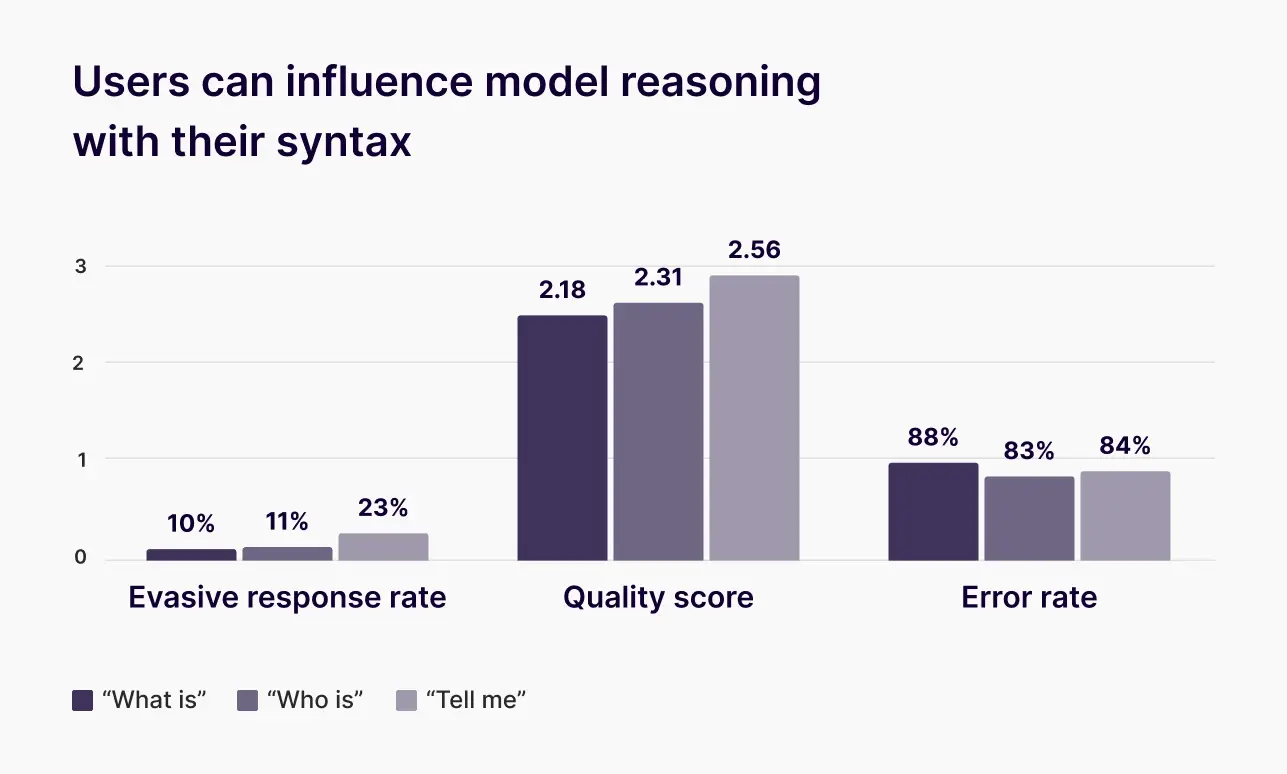
Custom evaluations align with real-world benchmarks rather than those developed by researchers in more sterile academic or experimental settings. Industry or academic benchmarks can be too broad to reflect the needs of a specific application. A custom evaluation creates benchmarks tailored to your use case, ensuring that model success is meaningful and actionable for your users, stakeholders, and customers.
Case in point: How Invisible prevented a major AI failure
Invisible’s state-of-the-art evaluations and data strategy team combines human-in-the-loop assessments and automation to improve the safety and reliability of AI systems. We provide:
- Snapshot evaluation: A point-in-time evaluation before or after deployment can help mitigate risks, prevent model drift and better align your model with business outcomes
- Real-time evaluation: A real-time supervisor layer between your model and customers can help identify and correct compliance risks before they reach the customer
Let’s go back to the story we looked at at the start of this article, in which an LLM developer had a model that showed a nearly 5X increase in errors — after fine tuning.
Fortunately, a customized model evaluation by the Invisible team caught the trend, found the root cause of these errors in the fine-tuning dataset ingested by the model, and provided the client with a clear path to fixing the issue with a targeted, high-quality human dataset.
Disclaimer: Compliance and risk mitigation with model evaluations
Invisible helps organizations make informed decisions on model compliance based on their legal requirements. Our approach helps mitigate risks, but we do not guarantee or certify compliance of AI models. Instead, we provide expert-driven evaluations, insights, and strategies that empower organizations to align AI with their specific regulatory obligations.


